AWS Step Functions: The Secret Weapon for Serverless Developers
In this post I’ll walk you through on how to use Step Functions (with an example) for the most common tasks, while giving a quick overview of JSONPath.
Overview
AWS Step Functions is a service that allows you to model complex workflows with little to no code. It is a state machine and uses a special language syntax call ASL or Amazon States Language to define states.
ASL allows you define Tasks that make up the state machine. Further, ASL allows you to define transition between these states. For example, make a call to a web service and if the response is successful, store the data in DynamoDB, otherwise log to CloudWatch logs.
JSONPath
One of the tricky parts of working with ASL is it’s use of JSONPath. If you’re not already familiar, JSONPath is a query language for JSON much like XPath for XML. It allows you to select and extract data from a JSON document. You use a JSONPath expression to traverse the path to an element in the JSON structure.
Here’s a quick example. Say you have the following JSON response from an API call
{
"pets": [
{
"name": "bruno",
"species": "dog"
},
{
"name": "felix",
"species": "cat"
}
]
}Say, you you want to get the name of the first pet, you would do so by using the JSONPath expression $.pets[0].name. $ is used to denote the root of the JSON document.
If you wanted to get the names of all the pets and ignore the other attributes you could do so by using the JSONPath expression $.pets[*].name . This would return [“bruno”, “felix"]. Simple, right? Don’t worry, you’ll get a hang of it as you use it more.
We’ll focus on the 80% use-case to get productive with Step Functions and not get too into the weeds of JSONPath itself.
JSONPath allows you to select and extract data from a JSON document
Diving In!
With that prelude out of the way, let’s dive in!
Like most of software engineering, the most effective way to understand a concept is with a concrete example. A client of mine needed a way to easily extract data from a document uploaded by a user. This document is a government issued document like a passport.
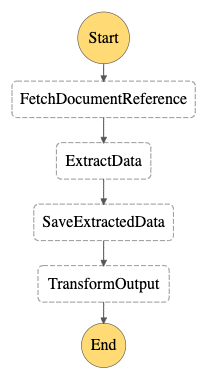
Here is the state machine definition using ASL.
{
"StartAt": "FetchDocumentReference",
"States": {
"FetchDocumentReference": {
"Next": "ExtractData",
"Type": "Task",
"ResultPath": "$.document",
"ResultSelector": {
"Item.$": "$.Item"
},
"Resource": "arn:aws:states:::dynamodb:getItem",
"Parameters": {
"Key": {
"id": {
"S.$": "$.docId"
}
},
"TableName": "DocumentTable",
"ConsistentRead": false
}
},
"ExtractData": {
"Next": "SaveExtractedData",
"Retry": [
{
"ErrorEquals": [
"Lambda.ServiceException",
"Lambda.AWSLambdaException",
"Lambda.SdkClientException"
],
"IntervalSeconds": 2,
"MaxAttempts": 6,
"BackoffRate": 2
}
],
"Type": "Task",
"ResultPath": "$.extractedData",
"ResultSelector": {
"data.$": "$.Payload.body"
},
"Resource": "arn:aws:states:::lambda:invoke",
"Parameters": {
"FunctionName": "arn:aws:lambda:us-east-1:123456789001:function:ExtractData",
"Payload.$": "$.document.Item"
}
},
"SaveExtractedData": {
"Next": "TransformOutput",
"Type": "Task",
"ResultPath": "$.savedExtractedData",
"ResultSelector": {
"Item.$": "$.Attributes"
},
"Resource": "arn:aws:states:::dynamodb:updateItem",
"Parameters": {
"Key": {
"id": {
"S.$": "$.docId"
}
},
"TableName": "DocumentTable",
"ExpressionAttributeValues": {
":val": {
"S.$": "$.extractedData.data"
}
},
"ReturnValues": "ALL_NEW",
"UpdateExpression": "set extractedData = :val"
}
},
"TransformOutput": {
"Type": "Pass",
"Parameters": {
"result.$": "$.extractedData"
},
"OutputPath": "$",
"End": true
}
}
}
If that looks intimidating, don’t worry. Once you read through it, you’ll see that it’s really quite simple. Like any language, it has it’s own unique syntax that takes a minute to get used to.
So what does this state machine do?
Application Flow
This application allows users to upload a document to AWS S3. Once uploaded, a reference to the S3 object is stored in DynamoDB. Then, an event is fired that kicks off our state machine.
When the state machine is started, it’s input is as follows. We’ll refer to this as the “input” or “state” from here on.
{
"docId": "some-document-id"
}Step 1 : Fetch from DynamoDB
Let’s zoom in and look at the first step. It gets the “row” from DynamoDB using the docId from the input. Here’s the task definition for this step:
{
"FetchDocumentReference": {
"Next": "ExtractData",
"Type": "Task",
"ResultPath": "$.document",
"ResultSelector": {
"Item.$": "$.Item"
},
"Resource": "arn:aws:states:::dynamodb:getItem",
"Parameters": {
"Key": {
"id": {
"S.$": "$.docId"
}
},
"TableName": "DocumentTable",
"ConsistentRead": false
}
}
}This defines a step of Type: "Task" which is configured to fetch a document from DynamoDB. Notice there’s no call to Lambda or anything. This step does all the heavy lifting of reaching out to DynamoDB and performing the necessary query. This is defined in the block:
{
"Resource": "arn:aws:states:::dynamodb:getItem",
"Parameters": {
"Key": {
"id": {
"S.$": "$.docId"
}
},
"TableName": "DocumentTable",
"ConsistentRead": false
}
}If you’re wondering “What the hell is S.$: $.docId ?” 🤔
Good question my astute reader! Let’s take a very small detour to understand why.
If you were to query DynamoDB, without JSONPath or Step Functions, your query would be something like like (using TypeScript).
// ... imports etc. Left out for brevity
new GetItemCommand({
TableName: 'foobar',
Key: {
id: {
S: 'foobar'
},
},
})This tells DynamoDB that the thing you’re looking up is of type String denoted by S and it has the value foobar. There are a few other types like M for Map , Nfor Number etc. We won’t go too deep into DynamoDB here, but you’re interested let me know in the comments and I’d be more than happy to get into detail in another post 👍🏻
… alrighty, back to the state machine.
Now that we know what Sis, what is S.$?S.$ tells the state machine that the value is dynamic and that we’ll use a JSONPath expression to get it as opposed the a static value. If you remember from our little JSONPath tutorial earlier, $.docId means that we’re picking the docId field from the root of the input — denoted by $ .
If we don’t use S.$ the value that will be used is the literal String "$.docId" .
Kinda neat, right?
Lastly, the output of this task needs to go somewhere. That’s defined as follows
{
"ResultPath": "$.document",
"ResultSelector": {
"Item.$": "$.Item"
},
}ResultPath tells Step Functions to append the result to the input (as opposed to OutputPath , which we’ll look at shortly). This adds a key called document to the root of the input.
ResultSelector tells Step Functions what to select from the output of the operation (dynamodb:getItem). If you don’t specify this, the entirety of the output will be put in $.document
DynamoDB returns a lot of data — read capacity, http metadata etc. — which we don’t need. ResultSelector allows us to, well, select parts of that result (starting to become quite intuitive with context, huh 😁) and trim out the rest.
Like before, Item.$ tells Step Functions to get data from DynamoDB query using JSONPath — $.Item is a JSONPath expression that works on the result from DynamoDB and not the input.
Here’s what the input looks like after this step.
{
"docId": "some-document-id",
"document": {
"Item": {
// ...
}
}
}Step 2: Extract Data with Lambda
At this point the document reference from DynamoDB (DDB) has been retrieved and the data is stored as part of the input under $.document.Item .
In this step we’ll call a lambda function with this data. We won’t look at the details of the lambda itself, as it is outside the scope of this artice. Here’s how the lambda is called from Step Functions
{
// ...
"Resource": "arn:aws:states:::lambda:invoke",
"Parameters": {
"FunctionName": "arn:aws:lambda:us-east-1:123456789001:function:ExtractData",
"Payload.$": "$.document.Item"
}
// ...
}Pretty straightforward, right? We’re calling an AWS Lambda using the ARN (Amazon Resource Name).Payload.$ tells Step Functions to call the Lambda with a JSON object with the key Payload , populated with data from our state machine input — $.document.Item . Easy peasy 👏🏻
Where does the output from the lambda go? Let’s see!
{
// ...
"ResultPath": "$.extractedData",
"ResultSelector": {
"data.$": "$.Payload.body"
}
// ...
}This tells Step Functions, like before, to append to the input of our state machine. Here we see ResultSelector again that tells Step Functions to select the body from the lambda response and place it inside the data key.
Note: In the ResultSelector , $.Payload is part of the Lambda response element and not from function code written by us. You can find a full reference below at the official documentation
https://docs.aws.amazon.com/step-functions/latest/dg/connect-lambda.html
Here’s what the input looks like after this step
{
"docId": "some-document-id",
"document": {
"Item": {
// ...
}
},
"extractedData": {
"data": {
// ...
}
}
}Step 4: Transformation
Before you say anything… no, that wasn’t a typo 😁 The step — SaveExtractedData — pretty much follows the same pattern of working with DynamoDB. So let’s skip that for now and look at something new!
{
// ...
"TransformOutput": {
"Type": "Pass",
"Parameters": {
"result.$": "$.extractedData"
},
"OutputPath": "$",
"End": true
}
// ...
}This one’s really interesting and I didn’t know it existed until I happened upon it in the docs.
Type: "Pass" is used to pass inputs to outputs without performing work such as calling a lambda function or querying DynamoDB. It is usually used for debugging your state machine but I chose to use it to transform the output of the entire flow.
Unlike what we’ve used so far, this task uses OutputPath as opposed to ResultPath . While ResultPath appends data to the input (or state), OutputPath replaces the input. Here we place the extractedData from our state — $.extractedData — and place it inside $.result .
Here’s what our final state looks like after this step
{
"result": {
// ... the extracted data
}
}Summary
Here’s a quick look at what you learned today.
$— Root of JSON object. Returns all data in the JSON document.$.someArray[0]— Returns the first item in the array.$.someArray[*]— Returns all items in the array.SomeKey.$: $.SomeOtherKey— A way to dynamically add keys with value from a JSONPath expression.ResultPath— Append data to the state (or input) of the state machine.OutputPath— Replace the data in the state (or input) of the state machine.ResultSelector— Extract data from the result of an operation.
Thank you so much for taking the time to read this article. This was something that I struggled with when I first started and I hope this article made the process of working with Step Functions easier.
If you liked it, I’d really appreciate a 👏🏻 or a comment.